[캡스톤B] 2. Colab을 이용한 YOLOv5 Custom 학습 및 Inference
해당 프로젝트는 현재 데이터 수집, Object Detection 모델 학습, 모델 실행 순으로 진행하는 중입니다. 이번 포스트에서는 YOLOv5 아키텍쳐 분석 및 Colab을 이용한 Custom 학습 등을 다루어 보려고 합니다.
2. Colab을 이용한 YOLOv5 Custom 학습 및 Inference
※ 쓰레기 무단 투기 행위 인식
앞 포스트에서 말씀드렸듯이 저희 프로젝트는 쓰레기 무단 투기 행위를 인식하는 시스템입니다. 쓰레기 무단 투기 행위 인식을 위한 방법으로 2가지를 고려 중인데요. 그 중 첫째는, 쓰레기와 사람 사이의 분리 시점을 계산하는 것입니다. 따라서 이번 글을 통해 사람과 사람 손 위에 있는 물건을 인식하고 이들의 좌표를 출력하도록 해보겠습니다. 차후 좌표들은 서버에 전달하여 Bounding Box가 서로 떨어지는 시점을 계산할 예정입니다.
※ Object Detection 모델 선정
Object Detection에는 아래와 같이 수많은 알고리즘들이 있습니다. 이번 프로젝트를 위해 사용할 알고리즘들로는 YOLO와 SSD 알고리즘이 있습니다. 그 중 저는 YOLO 알고리즘을 맡아 구현하기로 하였습니다.
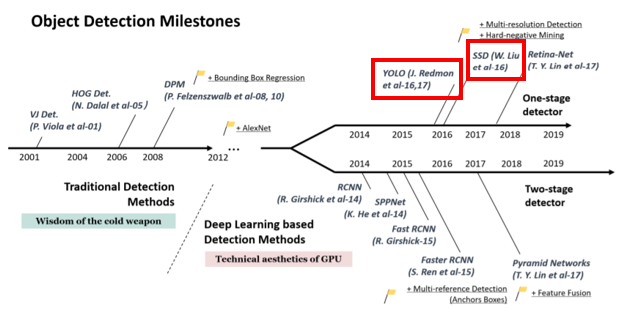
※ YOLO란?
Object Detection 모델 중 하나로, 1-Stage Detector로 객체를 인식하고, 좌표를 찾는 것이 동시에 이루어지는 모델입니다. YOLO는 속도가 빠르다는 점이 장점입니다.
Object Detection 모델이 이미지로부터 Feature map을 추출하는 부분을 Backbone, 추출된 Feature map을 바탕으로 물체의 위치를 찾는 Head로 나눌 수 있는 것처럼 YOLO도 마찬가지입니다.
아래 그림에서 Darknet 부분이 Backbone으로 YOLOv5에서는 yolov5-s, m, l, x 총 4가지 버전이 있습니다. Head에서는 Anchor Box(Default Box)를 처음에 설정하고 이를 이용해 최종적인 Bounding Box를 생성합니다. FCN layer들을 포함하고 있고, Class probability를 최종적으로 계산합니다.
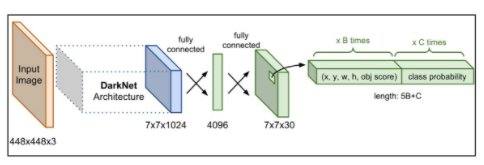
여기서는 이 YOLOv5 모델을 어떻게 사용하고 학습시키는지 집중적으로 다루려고 합니다.
※ Colab을 이용한 YOLOv5 Custom 학습
0) 개발 환경
모델 학습을 위한 환경으로는 Google Colab(https://colab.research.google.com/)을 이용하였습니다.
처음에는 AWS에서 사용하려 하였으나, AWS의 EC2는 CPU만 지원하는 반면, Colab은 무료로 12시간 정도의 GPU를 사용할 수 있기 때문입니다. 또한, 개발 프레임워크로 PyTorch를 사용하였습니다.
▷ Colab을 사용하기 위해서는 위의 사이트에 들어가 새 노트를 클릭합니다.
▷ 새 노트를 클릭하면 .ipynb 확장자의 노트북이 만들어집니다.
여기서 런타임을 눌러 런타임 유형을 GPU로 변경합니다.
▷ 저장을 누르면 이제부터 무료로 12시간의 GPU를 사용할 수 있습니다. 여기까지 개발 환경 세팅을 마쳤습니다.
1) 데이터 수집
앞서 저는 영상 데이터에서 프레임을 추출하여 학습 데이터를 얻었는데요. 이 이미지들을 이용해 Custom 학습을 진행하려고 합니다.
2) 데이터셋 만들기 - data.yaml 생성 및 라벨링
딥러닝 모델을 학습시키기 위해서는 학습 데이터의 경로, 클래스 개수, 종류가 적혀 있는 data.yaml 파일을 생성하고, 수집한 데이터에 클래스들을 라벨링 해준 후, YOLOv5 모델에 맞는 포맷으로 만들어야 합니다.
이러한 과정을 로컬에서 직접 할 수도 있겠지만 너무 번거로운워서.. 여기서는 상대적으로 간단한 라벨 툴인 Roboflow(https://app.roboflow.com/) 사이트를 이용해 데이터셋을 만들려고 합니다.
▷ Roboflow 사이트에 들어가 Create New Project를 클릭합니다.
▷ 새 프로젝트를 만들었으면 수집한 데이터들 중 학습 데이터로 사용할 이미지들을 업로드합니다.
무료 버전의 경우 한 프로젝트에 1000개까지 무료 업로드가 가능하다고 하니 참고해주세요.
▷ 이제부터는 정말 반복 작업의 시작입니다... 모델이 학습할 수 있도록 이미지 원하는 부분에 클래스라는 라벨을 붙여주는 작업입니다. 저는 우선 나중에 세분화해야겠지만, 사람과 사람 손에 있는 물체로 클래스를 나누었습니다. 마우스를 이용해 이미지의 원하는 부분에 박스를 그린 후, 클래스를 지정합니다.
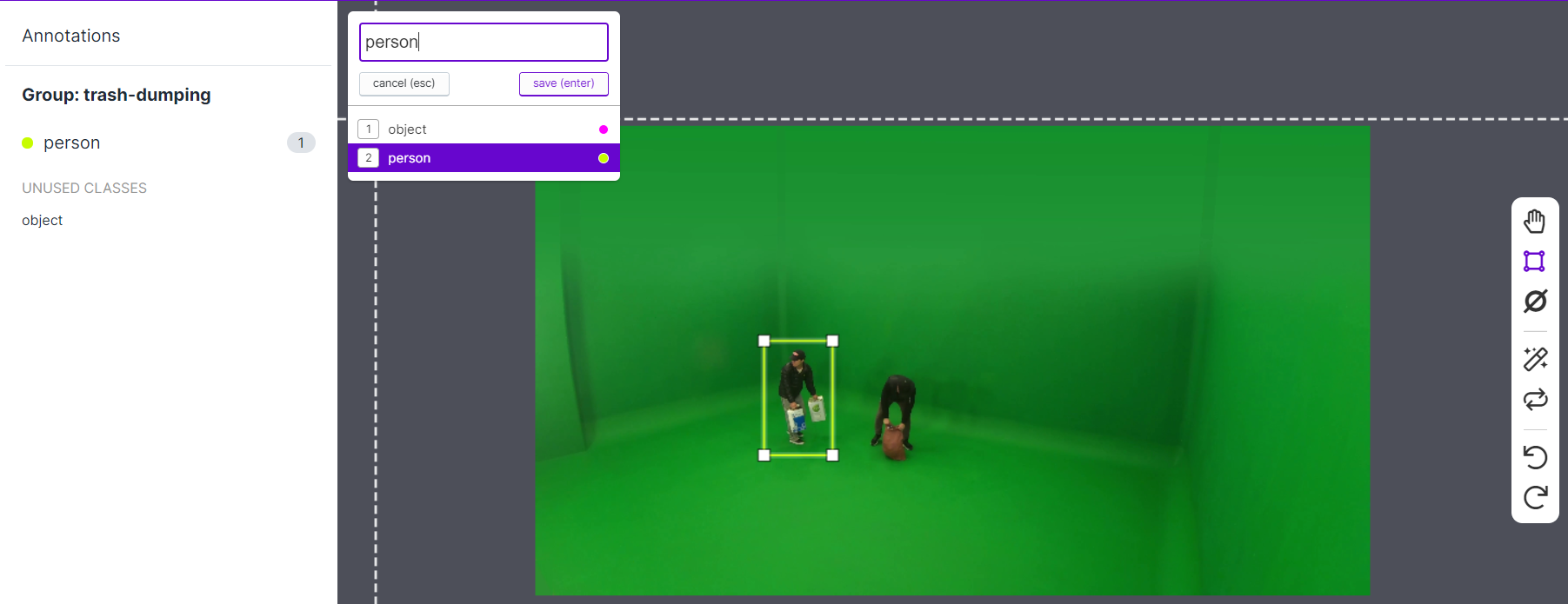
▷ 이 과정을 Unannotated, 라벨링하지 않은 이미지가 없을 때까지 반복하면 됩니다. 즉, 이미지 개수만큼 반복하라는 소리죠... 제가 라벨링한 프로젝트들 중 하나인데, 무료 버전의 경우 프로젝트 하나당 최대 1000개까지 라벨링할 수 있으니, 1000개의 데이터가 초과하면 프로젝트를 여러 개 만들어서 라벨링한 후, 폴더를 합쳐주시면 됩니다. 다들 화이팅, 저도 화이팅..!
▷ 모든 라벨링이 끝났다면 오른쪽 위의 청록색 Generate New Version을 누르면 됩니다. 데이터셋을 만들기 위해 여러 가지 버전을 만들 수 있으니 참고해주세요.
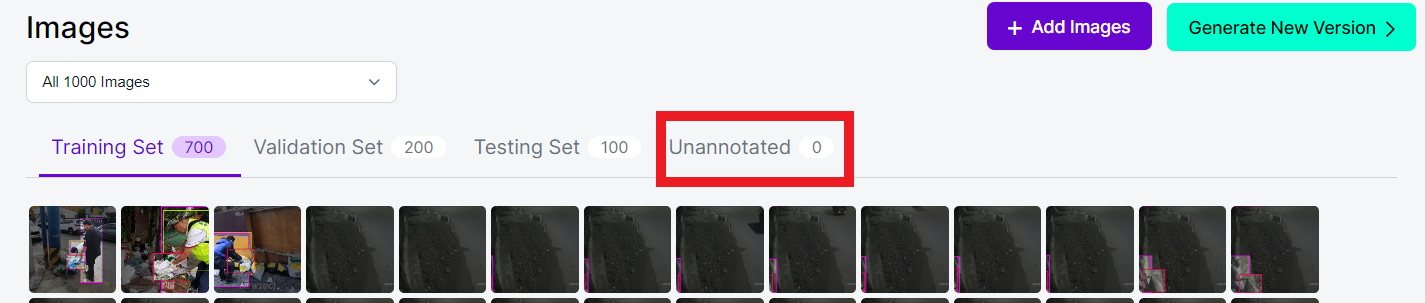
▷ 그러면 다음과 같이 Training Set, Validation Set, Testing Set을 어떤 비율로 분류할 것인지 지정하는 Train/Test Split 탭, Preprocessing 탭, Augmentation 탭, 최종적으로 Generate 탭을 볼 수 있습니다.
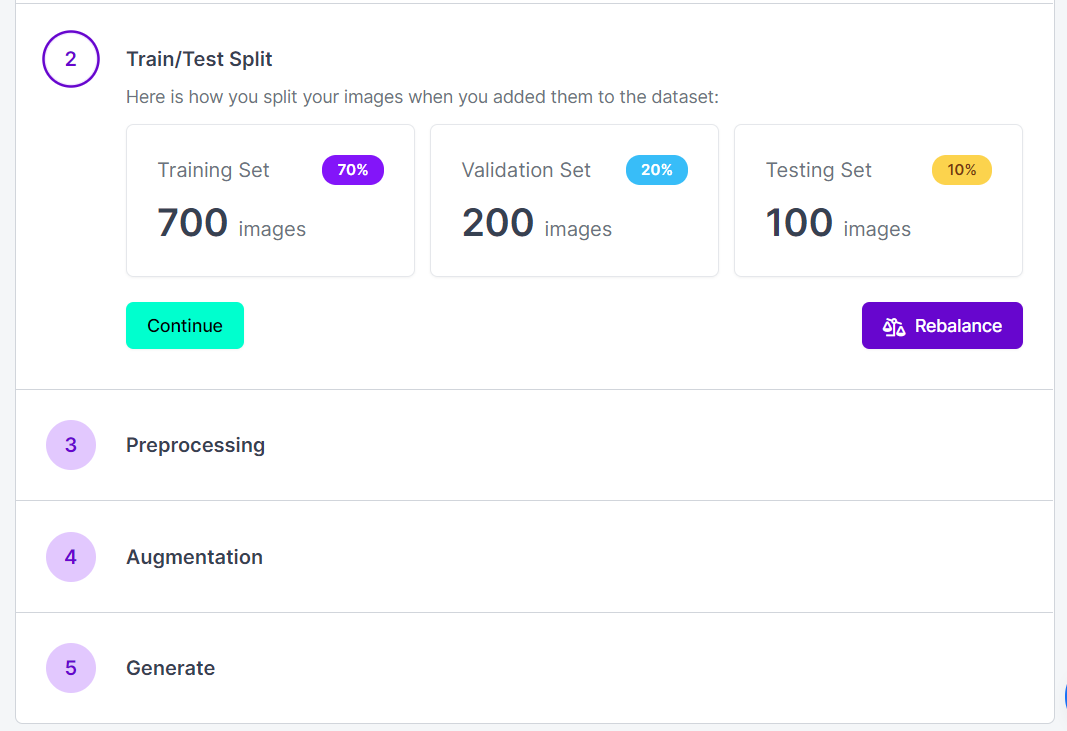
⊙ 아래 탭들은 필요한 부분만 선택하여 진행하면 됩니다.
- Train/Test Split
분석 모델을 만들기 위한 Train data,
여러 분석 모델 중 어떤 모델이 적합한지 선택하기 위한 Validation data,
최종적으로 선택된 분석 모델이 얼마나 잘 작동하는지 확인하기 위한 Test data,
이 3가지로 랜덤하게 분류해주는 기능입니다.
저는 아래 Colab에서 코드를 이용해 데이터를 분류하려고 하므로 Train data에 전부 넣었습니다.
- Preprocessing
데이터 전처리를 할 수 있는 기능으로, Scale 보정 등을 수행할 수 있습니다.
- Augmentation
성능을 높이기 위해 훈련 데이터를 변조하는 기능입니다.(ex) 상하좌우반전)
▷ Generate
마지막으로 Generate를 누르면 data.yaml이 자동으로 생성되고, 데이터셋 만들기가 완료됩니다.
여기서 데이터셋의 포맷을 지정할 수 있습니다.
저는 PyTorch를 이용하려고 하므로 YOLO v5 PyTorch를 선택하였습니다.
Export를 클릭하면 데이터셋을 다운로드 받을 수 있는 링크가 생성됩니다.
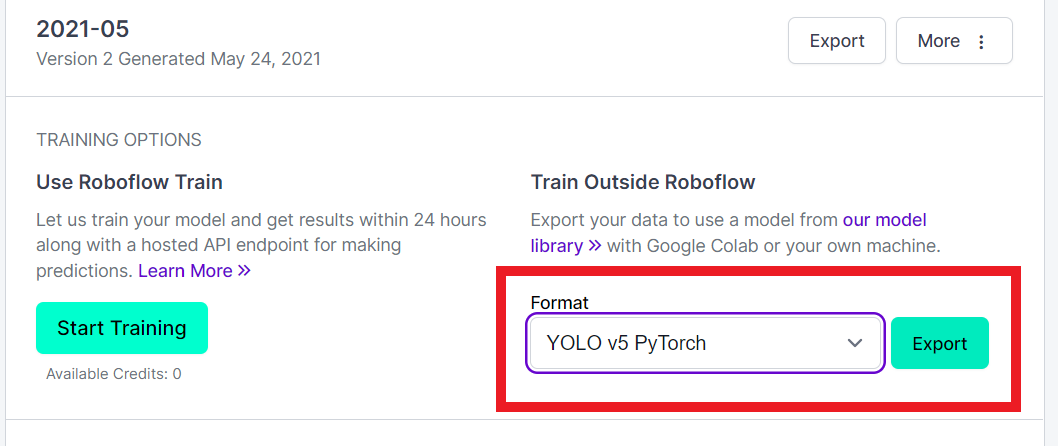
▷ Raw URL을 이용하면 로컬로 다운로드 받을 수 있지만, 저는 Colab 환경에서 다운로드 받기 위해 Jupyter 버전 명령어를 복사하였습니다. 이제 이 명령어를 Colab에서 사용해 YOLOv5 모델 학습을 진행할 예정입니다.
3) Colab을 사용하여 본격적인 YOLOv5 Custom 학습
%cd /content
!curl -L "dataset 링크 붙여넣기" > roboflow.zip; unzip roboflow.zip; rm roboflow.zip
%mkdir dataset
%mv test dataset
%mv train dataset
%mv valid dataset
%mv data.yaml dataset▷ 위에서 생성한 dataset 링크를 그대로 붙여넣으면 train, test, valid 폴더와 data.yaml 파일이 다운로드됩니다. 사용하기 편하도록 이들을 전부 dataset이라는 폴더에 이동시킵니다.
!git clone https://github.com/ultralytics/yolov5.git
%cd /content/yolov5/
!pip install -r requirements.txt▷ dataset을 다운로드 받았으면 YOLOV5 모델을 다운로드 받고, 필요한 모듈과 라이브러리들을 설치해야 합니다. 위의 명령어들로 https://github.com/ultralytics/yolov5.git 레포지토리를 클론하고, requirements.txt를 설치합니다.
%cd /
from glob import glob
img_list = glob('/content/dataset/train/images/*.jpg')
print(len(img_list))▷ train 폴더에 있는 이미지들 리스트를 glob 라이브러리를 이용해 가져옵니다.
from sklearn.model_selection import train_test_split
train_img_list, val_img_list = train_test_split(img_list, test_size=0.2, random_state=2000)
print(len(train_img_list), len(val_img_list))▷ 가져온 이미지 리스트를 훈련 데이터와 검증 데이터로 분류합니다. 저는 test_size=0.2로 하여 8:2로 랜덤하게 분류하였습니다.
with open('/content/dataset/train.txt', 'w') as f:
f.write('\n'.join(train_img_list) + '\n')
with open('/content/dataset/val.txt', 'w') as f:
f.write('\n'.join(val_img_list) + '\n')▷ 훈련 데이터와 검증 데이터로 분류한 리스트를 data.yaml에 업데이트합니다.
import yaml
with open('/content/dataset/data.yaml', 'r') as f:
data = yaml.load(f)
print(data)
data['train'] = '/content/dataset/train.txt'
data['val'] = '/content/dataset/val.txt'
with open('/content/dataset/data.yaml', 'w') as f:
yaml.dump(data, f)
print(data)▷ 폴더의 위치를 바꿨으니 훈련 데이터와 검증 데이터 경로를 재설정합니다.
%cd /content/yolov5/
!python train.py --img 416 --batch 16 --epochs 50 --data /content/dataset/data.yaml --cfg ./models/yolov5s.yaml --weights yolov5s.pt --name yolov5s_results▷ 드디어 학습을 시작합니다! Colab의 GPU가 없었다면 정말 얼마나 오래 걸렸을지 상상도 안되네요...
참고로,
--img는 이미지 크기,
--batch는 batch 사이즈로 작을수록 정확도가 올라갑니다.
--epochs는 전체 데이터를 훈련하는 횟수,
--data는 위에서 생성한 데이터셋 정보가 담긴 data.yaml 경로,
--cfg는 YOLOv5 아키텍쳐에 대한 정보가 담긴 yolov5s.yaml, yolov5m.yaml, yolov5l.yaml, yolov5x.yaml,
--weights는 모델 파일명(*.pt), --name은 결과를 저장하는 폴더 이름입니다.

%load_ext tensorboard
%reload_ext tensorboard
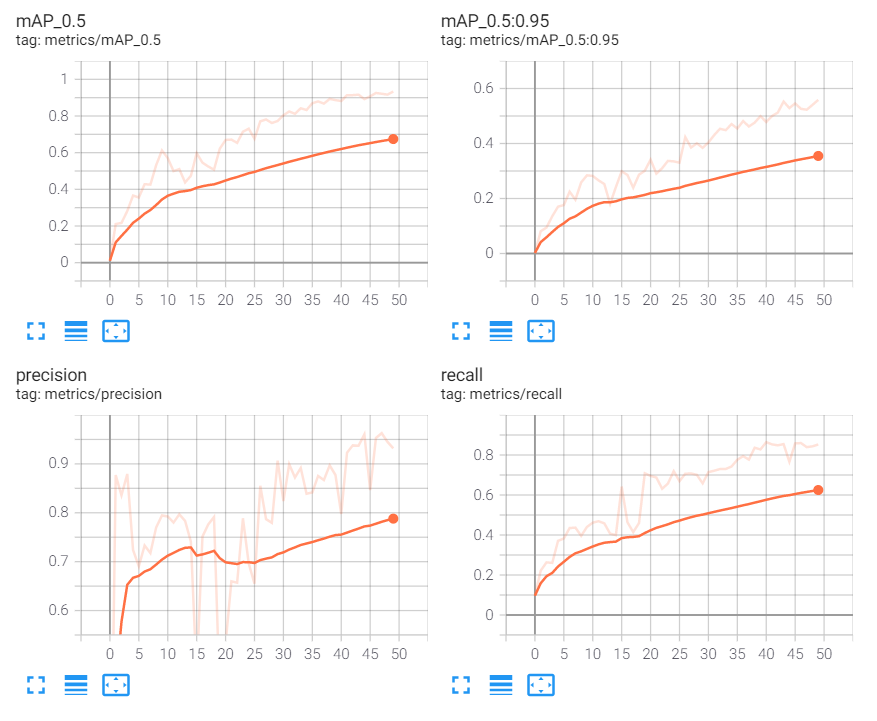
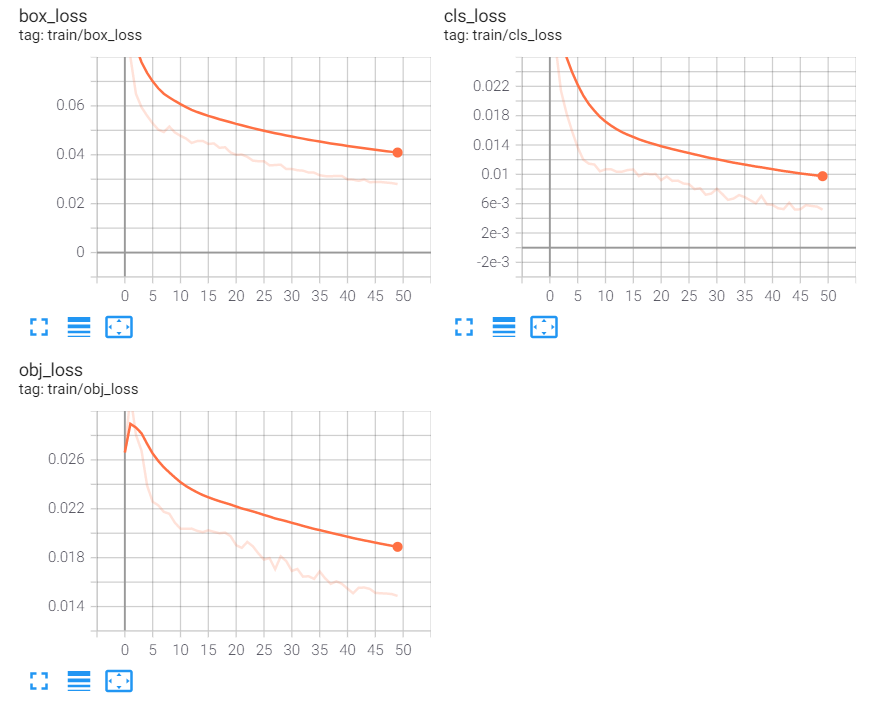
%tensorboard --logdir /content/yolov5/runs/▷ 학습 결과를 그래프로 확인합니다. 아직 정확도가 부족하지만, 그래도 Train 학습 그래프가 우상향하고, Loss 그래프는 우하향하는 것을 보니 모델이 제대로 학습되었다는 점을 확인할 수 있습니다.
4) 좌표 추출 & Video Inference
▷ 먼저 영상에 모델을 실행하기 전에 저는 인식한 객체들의 좌표가 필요했는데요. 사람과 사람이 들고 있는 물체의 좔표를 확인해야 했습니다. 차후 이 좌표들을 서버에 올려 분리 시점을 계산하는 데 사용할 예정입니다. YOLOv5 폴더의 detect.py에서 Print results, Write results 근처인 아랫 부분 코드를 찾아 det 행렬을 출력해주면 인식한 객체의 좌표를 출력할 수 있습니다.
# Process detections
for i, det in enumerate(pred): # detections per image
...
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
print(det)
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
...
# Print time (inference + NMS)
print(f'{s}Done. ({t2 - t1:.3f}s)')
▷ YOLOv5 모델 안에 있는 detect.py를 이용해 video에서 객체들을 인식합니다.
# video inference
%%time
!python detect.py --weights '/content/yolov5/runs/train/yolov5s_results/weights/best.pt' --img 1280 --conf 0.4 --source '/content/drive/MyDrive/Colab_Notebooks/160-2_cam01_dump02_place10_day_spring.mp4'▷ --weights 다음에 위에서 학습한 모델 경로명을 작성하고,
--source 다음에 추론할 비디오 경로명을 작성하여 실행하면 됩니다.
--img 다음에 이미지 크기를 넣고,
--conf는 0~1 사이 값의 conf_threshold로 저는 0.4로 지정하였습니다.
▷ 추론 결과, 객체들을 인식할 때마다 det가 오른쪽에
tensor([[1.30400e+03, 1.29200e+03, 1.43300e+03, 1.47200e+03, 6.82617e-01, 1.00000e+00],
[1.68400e+03, 0.00000e+00, 1.94000e+03, 4.50000e+02, 4.56543e-01, 2.00000e+00]]
와 같이 tensor 행렬의 형태로 객체들의 좌표까지 나오는 것을 확인할 수 있었습니다.
▷ det는 앞의 4개는 (x,y) 좌표들이고, 뒤에는 정확도와 클래스를 의미합니다.
즉 tensor 안에서 위의 행은 object의 좌표와 정확도이고, 아래 행은 person의 좌표와 정확도입니다.

%cd /content/yolov5/runs/detect/exp4
%mv 160-2_cam01_dump02_place10_day_spring.mp4 /content/drive/MyDrive/Colab_Notebooks/▷ video inference가 끝나면 드라이브에 저장한 후, 로컬 컴퓨터에 다운로드받아 확인합니다. 저는 5분 정도의 영상을 이용해 실행해보았는데 주의해야 할 점은 다운로드가 오래걸려서 다운로드가 끝나기 전에 런타임에 오류가 발생합니다. 따라서 드라이브에 저장한 다음 실행하는 것을 추천드려요.
▷ 모델을 이용해 객체 인식한 영상을 실행해보았지만 아직 제가 object 클래스의 이미지들을 넉넉하게 라벨링하고 학습시키지 않아서...
person 클래스 정확도보다 낮게 나오네요. 앞으로 더 학습시키면서 정확도를 올려보려고 합니다.
또한, Object Detection이니 만큼 기둥과 같이 사각지대 부분에 대해서도 더 고려해서 학습을 시켜야 봐야겠다는 생각이 들었습니다.
약간 후회가 되는 점은... 왜 제가 person과 object 클래스 라벨의 색깔을 똑같이 만들었을까요...
다시 학습시킬 때는 라벨 색깔이 확실히 구별될 수 있도록 색깔을 바꿔서 실행해야겠다고 다짐했습니다!