
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 유니티
- 회의실 배정
- 탄막 스킬 범위
- 탄막
- mysqld.sock
- 단어 수학
- 강의실2
- 영상 프레임 추출
- 우분투
- 토글 그룹
- SWEA
- 원형
- 문자열 압축
- 3344
- 18249
- 탄막 이동
- 알고리즘 목차
- 수 만들기
- 걷는건귀찮아
- 마우스 따라다니기
- 2020 KAKAO BLIND RECRUITMENT
- MySQL
- c#
- 3273
- 그리디알고리즘
- 윈도우
- AI Hub
- 알고리즘
- 백준
- 자료구조 목차
- Today
- Total
와이유스토리
[캡스톤B] 1. 영상 데이터 프레임 추출 본문
이번 블로그에서는 데이터 수집을 위한 영상 데이터 프레임 추출을 다루어 보려고 합니다.
이외의 포스트들 : https://whyou-story.tistory.com/search/%EC%BA%A1%EC%8A%A4%ED%86%A4
1. 영상 데이터 프레임 추출
※ 영상 데이터 수집
쓰레기 무단 투기 행위 학습을 위해서 가장 먼저 관련 데이터들이 필요했습니다.
처음에는 웹에서 크롤링하여 데이터를 수집하였으나, 데이터 수가 모델 학습하는 데에 턱없이 부족했어요.
그렇게 방황하던 중 AI Hub (https://aihub.or.kr/)라는 사이트에서 이상행동 CCTV 영상 AI데이터 카테고리에서 투기데이터를 발견하였습니다. AI Hub는 인공지능 학습용 데이터들을 모아놓은 플랫폼입니다. 저도 팀원 분께서 알려주셔서 처음 접속해보았는데 생각보다 많은 데이터들이 있어서 데이터 수집할 때 참고하시면 좋을 것 같아요!

위와 같이 키워드 검색에서 이상행동을 검색하면 여러가지 이상행동 데이터가 많이 나옵니다. 여기서 저는 투기 데이터를 이용하려고 헤요. 다만 데이터를 신청하면 승인받는데 약 하루정도 걸립니다... 주말에 신청했더니 월요일까지 기다려야만 했어요ㅠㅠㅠ
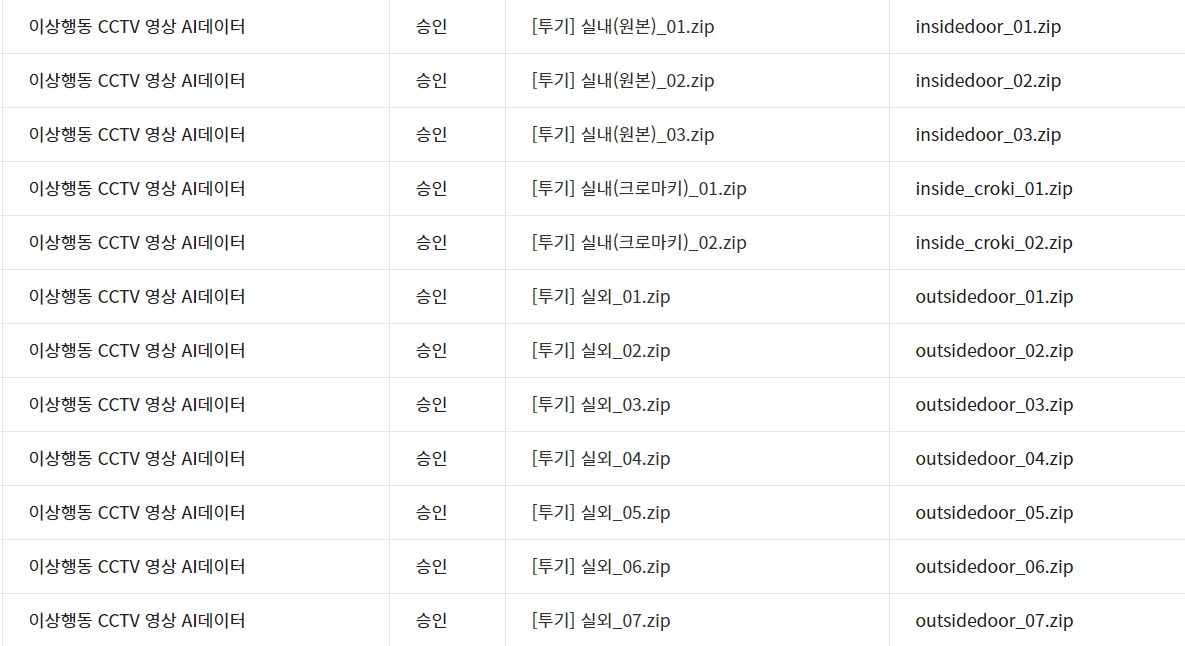
이렇게 투기 영상 데이터를 승인받았습니다! 오른쪽의 ~.zip 부분을 누르면 해당 영상 데이터를 다운로드 받을 수 있어요. 하지만 문제는 여기서 끝이 아니었죠... 영상 데이터인지라 크기가 어마무시하게 크더라구요. 압축을 했음에도 불구하고 한 파일당 거의 30GB가 되는크기였습니다. 제 컴퓨터의 3분의 2를 차지하였음에도 용량 부족으로 전부 다운로드받지 못했어요...
그래서 영상 데이터를 다운로드 받는 즉시 영상 데이터에서 프레임을 추출하기로 하였습니다!
※ 영상 데이터 프레임 추출
1) OpenCV 설치
저의 개발 환경은 윈도우이고, 개발 툴로 VSCode, 언어는 Python을 사용하였습니다.
▷ 먼저, 영상 데이터 프레임 추출을 위해 OpenCV를 설치합니다.
저의 경우 pip라는 파이썬 패키지를 설치하고 관리하는 패키지 관리자를 이용해 설치하였습니다. pip는 윈도우에서 python을 설치하면 자동으로 설치됩니다. 처음에는 이런게 왜 필요하지 싶었는데... 한 번 설치하면 요긴하게 사용하긴 하는 것 같아요!
py -m pip install opencv-python▷ 위의 명령어로 OpenCV를 설치합니다. 버전에 따라 다르다고 하는데 요즘 pip들은 앞부분에 py -m이 아닌 다른 명령어로는 윈도우에 설치가 안 되더라구요. 오랜만에 사용했더니 여기서 또 굉장히 헤맸네요... 참고해주세요!
2) 경로 설정
영상 데이터에서 프레임을 추출할 때 가장 중요한 것은 경로 설정입니다. 경로 잘못 설정하면 아무것도 안됩니다ㅠㅠㅠ 에러도 잘 안 뜨고, 이미지들 저장도 안 될 때도 있어요. 만약 그렇다면 대부분 '아 내가 경로 설정을 잘못했구나'라고 생각하시면 돼요. AI Hub에서 제공한 영상 데이터들이 폴더 안의 폴더 안의 영상들!!! 이런 느낌이라 더더욱 신경써서 작성하였습니다.
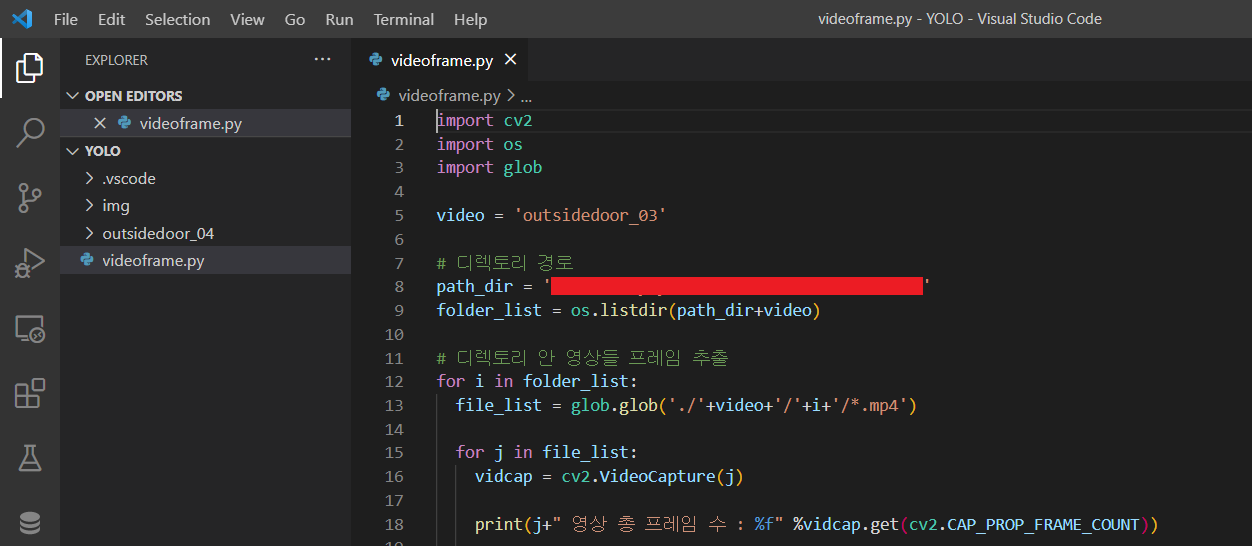
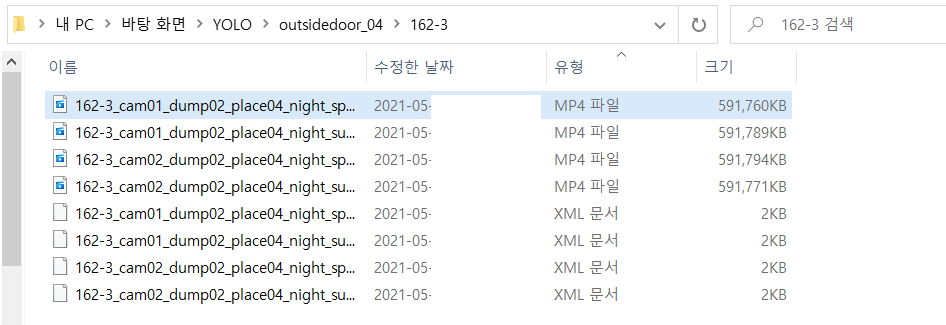
▷ 차근차근 설명하자면, AI Hub에서 다운로드 받은 영상 데이터의 경우 데이터가 굉장히 많아서 분류가 되어있습니다. YOLO라는 폴더 안에 위의 AI Hub에 있던 투기 데이터들 중 outsidedoor_04.zip을 압축 해제하여 outsidedoor_04로 저장하였고, 안에 보면 162-3, 162-4, ... 와 같은 폴더들이 저장되어 있어요.
같은 숫자의 경우 같은 장소 및 시간에서 촬영한 영상인데 카메라 각도가 다르거나 사람들 혹은 행동이 조금씩 다릅니다. 이러한 영상들이 mp4로 저장되어 있고, 영상을 설명하는 xml파일들이 저장되어있습니다.
즉, outsidedoor_04에 저장되어 있는 영상 데이터들을 videoframe.py에서 영상 프레임을 추출하여, img 폴더에는 outsidedoor_04와 같이 해당 영상 데이터에서 추출한 프레임을 jpg 형식으로 저장할 예정입니다.
▷ 디렉토리 구조를 도식화하자면 아래와 같습니다.
YOLO/
├── outsidedoor_04/ - 다운로드 받은 영상 데이터 outsidedoor_04.zip 해제
│ └── 162-3, 162-4, ... 폴더들
│ └── mp4, xml 파일들
├── img/ - 추출한 프레임 저장할 폴더
│ └── outsidedoor_04/
│ └── jpg 파일들
│
└── videoframe.py - 영상 프레임 추출3) 프레임 추출
이제부터 영상 데이터에서 프레임을 추출하는 코드를 작성해보려고 합니다. videoframe.py라는 파일에서 작성할게요.
import cv2
import os
import glob
video = 'outsidedoor_04'
# 디렉토리 경로
path_dir = './'
folder_list = os.listdir(path_dir+video)
▷ 먼저 cv2, os, glob 라이브러리를 import합니다. cv2로 프레임을 추출하고, os와 glob로 영상 데이터의 경로들을 지정해줄거에요.
video 변수에 다운로드 받은 폴더명을 저장하고, path_dir에는 YOLO 디렉토리, 즉 영상 데이터들과 videoframe.py가 저장되어 있는 경로를 저장합니다.
folder_list 변수에 os 라이브러리의 listdir을 이용하면 YOLO/outsidedoor_04에 저장되어 있는 모든 폴더의 리스트를 가져올 수 있어요. 여기서는 162-3, 162-3... 이런 폴더명들이겠네요.
# 디렉토리 안 영상들 프레임 추출
for i in folder_list:
file_list = glob.glob('./'+video+'/'+i+'/*.mp4')
for j in file_list:
vidcap = cv2.VideoCapture(j)
print(j+" 영상 총 프레임 수 : %f" %vidcap.get(cv2.CAP_PROP_FRAME_COUNT))
▷ 본격적으로 프레임 추출을 위해 glob.glob 함수로 mp4 파일들을 가져올게요. 이를 사용한 이유는 위의 그림에서 보았듯이 폴더에 xml 파일들이 mp4 파일들과 같이 저장되어 있었기 때문입니다!
mp4만 들어있는 폴더였다면 필요없는 부분일 거에요... 하지만 AI Hub에서 제공한 영상 데이터에는 모든 폴더에 xml파일이 들어있기에... 일일이 삭제하는 것보다는 코드 한 줄 짜는 게 빠르겠다 싶어서 작성하였습니다!
▷ cv2.VideoCapture(파일)을 이용해 video를 가져와 vidcap에 저장합니다. vidcap.get(cv2.CAP_PROP_FRAME_COUNT)를 이용하면 해당 영상의 총 프레임 수를 알 수 있어요.
count = 1
success = True
while success:
success, image = vidcap.read()
# 프레임
frame = int(vidcap.get(1))
if(frame % 60 == 0):
# 이미지 사이즈 변경
# image = cv2.resize(image, (960, 540))
title = './img/'+video+'/'+os.path.basename(j)+"_%d_frame_%d.jpg" % (count, frame)
cv2.imwrite(title, image)
print(title+" 저장")
count += 1
▷ 저는 60프레임마다 이미지를 추출하기로 하였는데요. 그 이유는 영상 데이터이기도 하고, 제가 사용하는 영상들은 사람들이 움직이는 영상이라 프레임이 하나하나씩 바뀔 때마다 영상의 장면들이 급격하게 변하지 않기 때문이에요.
▷ vidcap.read()를 이용해 해당 영상의 순간순간 이미지를 가져옵니다. 이미지를 가져오는 데 성공하면 success가 True로 바뀌어요. vidcap.get(1)은 가져온 이미지의 프레임 수를 가져옵니다. 소수점은 상관없을 정도의 작은 숫자니까 int로 바꿔 가져옵니다.
▷ 이제 60프레임마다 이미지를 저장할 건데요. if(frame % 60 == 0)에서 frame을 60으로 나눴을 때 나머지가 0이면 60프레임마다 if문이 실행되겠죠? 여기서 image를 본인이 원하는 사이즈로 바꿉니다. 저는 960 * 540 사이즈로 바꿀게요.
▷ 마지막으로 저장만 하면 끝입니다! cv2.imwrite(경로+제목, 이미지)를 이용해 저장하면 되는데요. 저는 img라는 폴더에 video와 영상 제목을 이용해 저장하였습니다.
▷ 이 때 주의해야 할 것은 해당 경로의 폴더가 꼭 존재해야 해요! 제가 img라는 폴더 안의 video, 즉 저의 경우 outsidedoor_04라는 폴더를 생성하지 않은 채 코드를 실행하고 기다렸다가 단 한 장의 이미지도 저장되지 않은 채 시간 낭비를 했더라죠...흑 꼭 해당 경로의 폴더를 만들고 코드를 실행해주세요.
.

▷ 이제 해당 폴더에 들어가면 60프레임마다 이미지가 저장되는 것을 볼 수 있습니다!
코드 작성할 때는 분명 간단해보이고 오래 안 걸릴 줄 알았는데, 제가 원하는 경로에 원하는 프레임 이미지를 저장하는데 생각보다 많이 헤매서 힘들었어요. 데이터 수집하는 게 이렇게 오래걸릴 줄은... 상상도 못했네요. 도움이 되면 좋겠어서 아래의 videoframe.py 코드 올립니다.
※ 참고) videoframe.py
import cv2
import os
import glob
video = '폴더명'
# 디렉토리 경로
path_dir = '디렉토리 경로'
folder_list = os.listdir(path_dir+video)
# 디렉토리 안 영상들 프레임 추출
for i in folder_list:
file_list = glob.glob('./'+video+'/'+i+'/*.mp4')
for j in file_list:
vidcap = cv2.VideoCapture(j)
print(j+" 영상 총 프레임 수 : %f" %vidcap.get(cv2.CAP_PROP_FRAME_COUNT))
count = 1
success = True
while success:
success, image = vidcap.read()
# 프레임
frame = int(vidcap.get(1))
if(frame % 60 == 0):
# 이미지 사이즈 변경
# image = cv2.resize(image, (960, 540))
title = './img/'+video+'/'+os.path.basename(j)+"_%d_frame_%d.jpg" % (count, frame)
cv2.imwrite(title, image)
print(title+" 저장")
count += 1
영상 데이터에서 프레임을 추출해 학습 데이터를 얻었으니 이어서 Object Detection 모델 중 하나인 YOLOv5 모델 학습에 대해 다루어보도록 하겠습니다.
'프로젝트 > 인공지능' 카테고리의 다른 글
| [캡스톤B] 3. OpenPose를 이용해 손의 위치 파악하기 (0) | 2021.05.25 |
|---|---|
| [캡스톤B] 2. Colab을 이용한 YOLOv5 Custom 학습 및 Inference (3) | 2021.05.17 |
